 AI for Data Cleaning: How AI Can Clean Your Data and Save You Hours and Money AI for Data Cleaning: How AI Can Clean Your Data and Save You Hours and Money Sep 12th 2025, 15:00 by Prasanna Chitanand Dirty data is the bane of the analytics industry. Almost every organization that deals with data has had to deal with some degree of unreliability in its numbers. According to the Pragmatic Institute, data practitioners spend 80% of their time identifying, cleansing, and arranging data and 20% analyzing it. This 80/20 rule is referred to as the Pareto Principle. |  Quantum Machine Learning (QML) for Developers: A Beginner's Guide Quantum Machine Learning (QML) for Developers: A Beginner's Guide Sep 12th 2025, 14:00 by Chandrasekhar Rao Katru Quantum computing is transforming artificial intelligence. Traditional AI faces challenges in optimization, large-scale data processing, and security. Quantum machine learning (QML) integrates quantum mechanics with AI, offering advantages such as: - Faster AI model training and inference
- Better pattern recognition and optimization
- Improved security using quantum cryptography
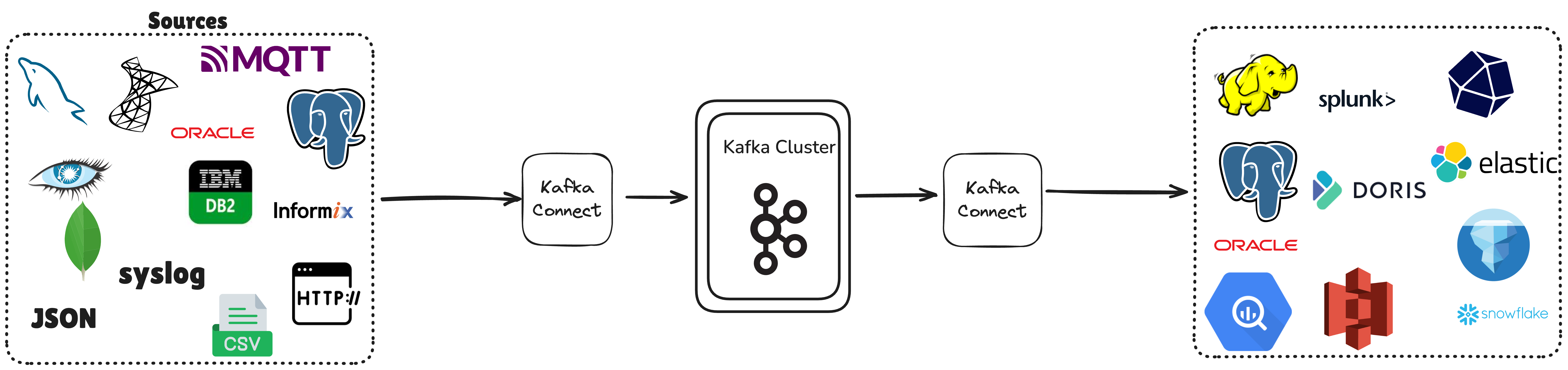
This guide covers practical implementations using: |  Demystifying Kubernetes on AWS: A Comparative Analysis of Deployment Options Demystifying Kubernetes on AWS: A Comparative Analysis of Deployment Options Sep 12th 2025, 13:00 by Aruun Kumar Kubernetes has become the industry-standard platform for container orchestration, offering automated deployment, scaling, and management of containerized applications. Its ability to efficiently utilize resources, abstract infrastructure complexities, and provide robust enterprise features makes it essential for modern application infrastructure. While Kubernetes can run on-premises, deploying on AWS provides significant advantages, including on-demand scaling, cost optimization, and integration with AWS services for security, monitoring, and operations. With multi-AZ high availability and a global presence in 32 regions, AWS delivers the reliability needed for mission-critical applications. |  The Real-time Data Transfer Magic of Doris Kafka Connector's "Data Package": Part 1 The Real-time Data Transfer Magic of Doris Kafka Connector's "Data Package": Part 1 Sep 12th 2025, 12:00 by Michael Hayden Apache Doris provides multi-dimensional data ingestion capabilities. In addition to the built-in Routine Load and Flink's support for reading from Kafka and writing to Doris, the Doris Kafka Connector [1], as an extended component of the Kafka Connect ecosystem, not only supports importing Kafka data into Doris but also relies on the vast Kafka Connect ecosystem to achieve the following features [2]: Rich Format Support - Natively parses complex formats such as Avro/Protobuf.
- Automatically registers and converts schemas.
- Optimizes the efficient processing of binary data streams.
Heterogeneous Integration of Multiple Data Sources - Relational databases: MySQL, Oracle, SQL Server, DB2, Informix, etc.
- NoSQL databases: MongoDB, Cassandra, etc.
- Message queue systems: ActiveMQ, IBM MQ, RabbitMQ, etc.
- Cloud data warehouses: Snowflake, Google BigQuery, Amazon Redshift, etc.
![Heterogeneous integration of multiple data sources]()
|  Tuples and Records (Part 4): Optimize React and Prevent Re-Renders Tuples and Records (Part 4): Optimize React and Prevent Re-Renders Sep 12th 2025, 11:00 by Guhaprasaanth Nandagopal Part 4 dives into React, showing how Tuples and Records can cut down unnecessary re-renders. By using immutable, value-based data structures, React can efficiently detect state changes, keeping your components lean and fast. We'll explore why re-renders happen and how adopting Tuples and Records simplifies state management while boosting performance. Also read: | |









Comments
Post a Comment